Continuous integration can be a tough sell to managers. It’s hard to describe the need for extra time and resources to build automated tests that should mimic what is already being done by developers. This advocacy can be especially difficult early in development when CI failures are common and the pipeline will need a lot of work. Why would any manager want a tool that creates more problems and interferes with the development cycle? A robust continuous integration pipeline is vital during development since it protects from the deployment of broken code and will generate more issues to remove bugs before production. Since Orbital Bus is an internal project, we decided to use it as an opportunity to build the kind of CI pipeline we always wanted to have on client sites.
Early on we looked at the possibility of automated provisioning of multiple machines for integration tests. We looked at a variety of tools including Vagrant, Salt Stack, and Chef and Puppet. What we found is that this automation was not worth the time investment. This post is supposed to be about the value of investing in a CI pipeline, so why are we talking about work we abandoned? To demonstrate that the value of a CI pipeline has to be proportionate to the time cost of maintaining it. When it came to automated provisioning we realized that we would spend more time maintaining that portion of the pipeline than reaping the benefits, so we stood up the VMs manually and replaced provisioning with a stage to clean the machines between runs.
As development progressed, we added to our pipeline, making sure that the time investment for each step was proportionate to the benefits we were receiving. Gradually we added the build process, unit tests, and automated end-to-end integration tests. As we continued to experiment we began using the GitLab CI runners to enhance our testing. We also discovered that GitLab could integrate with Jenkins, and brought our pipelines together to create an integrated dashboard on GitLab. As we neared the public release, we added a whole new stage for GitLab pages to deploy our documentation.
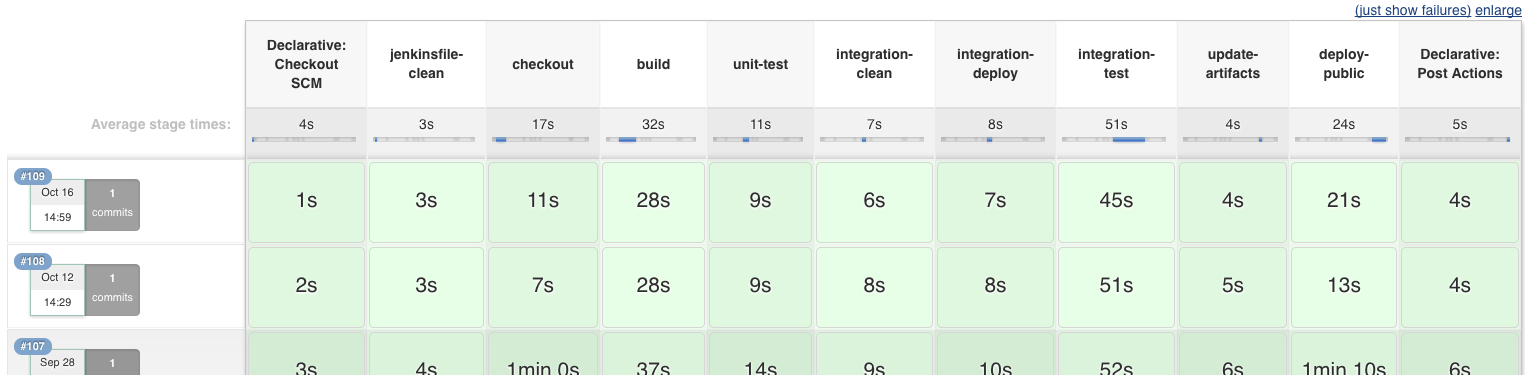
As the saying goes, Rome was not built in a day. Neither was our continuous integration. We added to it gradually, and as we did we had to overcome a number of obstacles. Our greatest problem has been false negatives. False negatives immediately negate the benefits of continuous integration because the team stops respecting the errors being thrown by the system. At one point, our disregard for the failures on the CI pipeline prevented us from noticing a significant compatibility error in our code. Each failure was an opportunity for us to understand how our code was running on multiple platforms, to explore the delta between development and production environments, and ultimately made our solution more robust. From the perspective of productivity it was costly, but the time greatly outweighed the value of hardening of our solution.
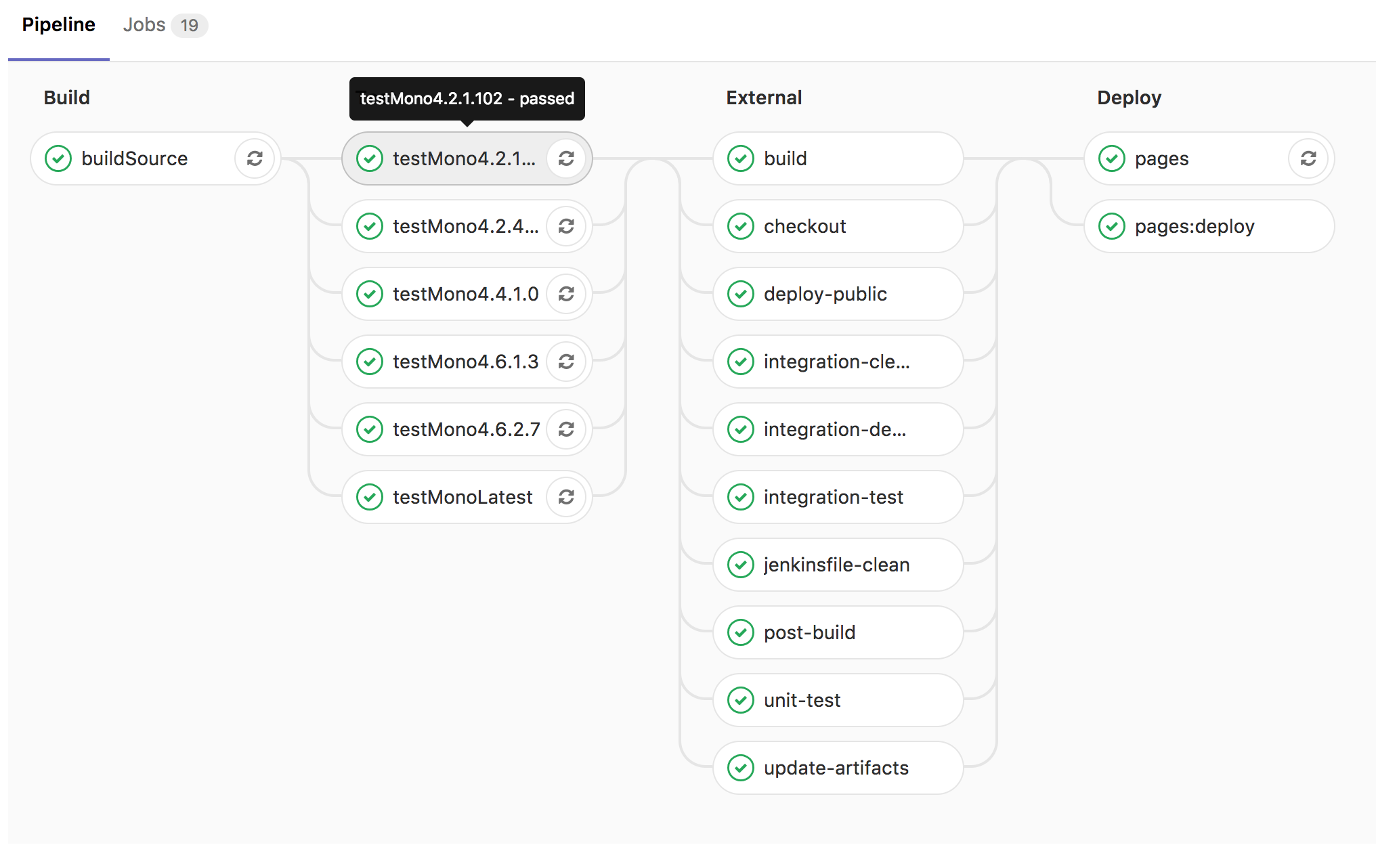
You would be mistaken if you thought we’ve stopped working on our pipeline. We have plans to continue to grow our CI, expanding our integration tests to include performance benchmarks and to work with the multiple projects which have originated in the Orbital Bus development. These additional steps and tests will be developed alongside our new features, so as to integrate organically. As our solution matures, so will our continuous integration, which means we can continue to depend on it for increased returns in our development cycle.